


日本の大阪大学の研究者らは、機能的磁気共鳴画像法(fMRI)によって得られた人間の脳活動の画像を再構成する新しい方法を提案するプレプリント形式の出版物(または英語のプレプリント、まだ査読されていない)を共有しました。

得られた画像は、その高解像度と高忠実度で印象的です。
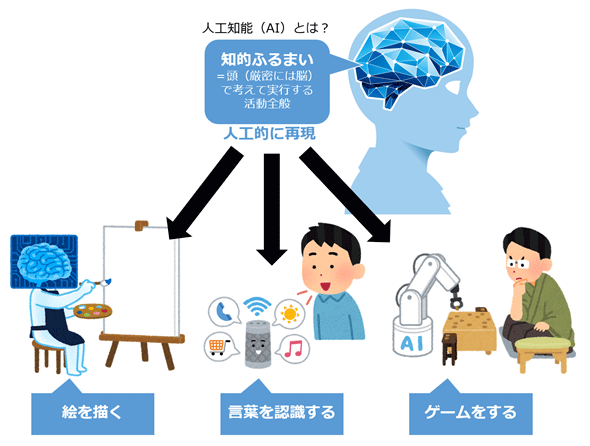
心を読む人工知能(AI)?
いいえ、彼女はまだ心を読めませんし、ハリウッド映画に出てくるような人工知能の一人ではありませんが、それでも興味深いアプローチです。 Microsoftによれば、研究者らはいわゆる安定拡散モデル(英語、Stable Diffusionから)を使用し、機械学習を通じて「使えば使うほど、求めているものを満たすより多くの結果が得られるように学習する」という。
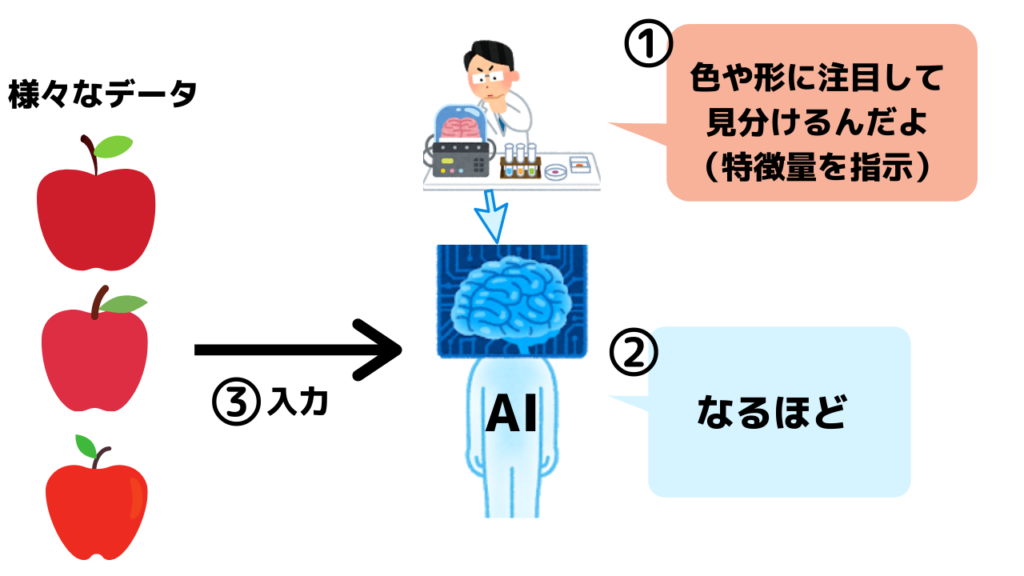
「その名前は、それが拡散モデルで動作し、何もないところから画像を作成するという事実に由来しています。しかし、その過程で、それはいくつかの潜在的な構造を使用して、それ自体を訓練し、この中で生成される歪みを軽減することができます」 AI の種類」 –マイクロソフト
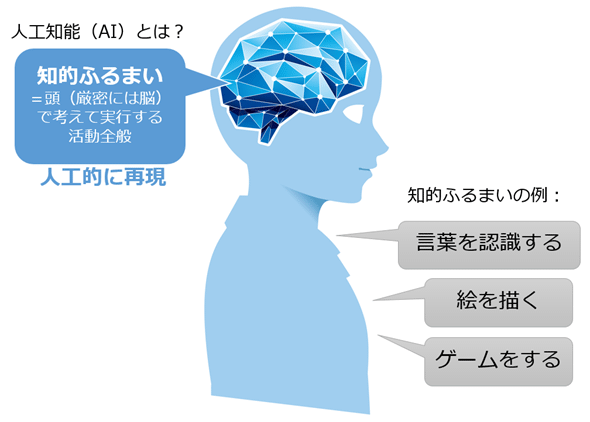
結果の背後にある科学
これはどういう意味ですか?この AI には、特定の画像 (テディベア、飛行機、スノーボード、時計塔) を見た参加者の脳活動反応に基づいて、特定の画像を認識することを学習する、いわゆる「セマンティック デコーダ」が搭載されています。これらの画像を認識する準備が整うと、デコーダは参加者の fNMR データを受信し、このデータから画像を再作成しようとします。
地域の進歩
この進歩は、脳活動の記録の最適化と改善のおかげであり、これと並行して、これら 2 つのネットワーク (生物学的および人工的) の画像表現間の対応関係を直接比較できる人工ニューラル ネットワーク モデルの作成により、どのように機能するかについての理解が深まりました。彼らは働いています。
研究者が使用する安定拡散モデルは、トレーニング段階で計算をより効率的に実行できることに加えて、計算処理コストを削減することができます。これは、提示された画像(この場合、人が見て、それに応じて fNMR データを使用したモデルによって処理された画像)に忠実な高解像度画像の生成に貢献します。

私たちの頭の中で何が起こっているかを学ぶ
高解像度の画像 (この投稿の冒頭の画像など) から、研究参加者が見た画像と比較して、モデルによって再現された画像の間にノイズや微妙な違いがあることに気づきました。研究者らによると、再構成におけるこうした違いは、たとえば、視覚体験が各個人に特有であり、モデルがさまざまな参加者からのデータを使用しているという事実による可能性があります。
研究者らによると、このモデルは、私たちが見る画像の初期処理を担当する脳の領域である視覚野からの活動信号を処理する際に、脳の他の領域と比較して高いパフォーマンスを示したという。
人間の考えていることを表示するデバイスというフィクションが、いつか現実に近づく日が来るかもしれません。
:max_bytes(150000):strip_icc()/20040720gemininorthopen01-5c4a7d78c9e77c000181f020.jpg?resize=768,501&ssl=1 "世界最大の天文台: ジェミニの発見")

